CUDA: Cooperative Groupsについて
NVIDIAのblog を読んでいたのですが良く分からなかったのでコードを動かしながら見ていきます。
Cooperative Groups とは?#
今までは__syncthreads()を使わないと同期できませんでした。しかし、これよりも小さなグループで同期を取りたいことがあります。Cooperative GroupsはCUDA 9から導入された機能で、これを使うことによって柔軟な同期が可能になります。
cooperative_groups.hをincludeするだけで使うことができます。そして、一般的にcgとaliasされることが多いようです。
#include <cooperative_groups.h>
namespace cg = cooperative_groups;
これより先のコードではこの定義を使うため注意してください。
Thread Group#
Cooperative Groupsの中でも最も基本の型はthread_groupです。threadの数やthreadのindex ([0, size - 1]) は次のように取得できます。
__global__ void my_kernel() {
cg::thread_block block = cg::this_thread_block();
printf("size: %d, thread_rank: %d\n", block.size(), block.thread_rank());
}
int main() {
my_kernel<<<2, 4>>>();
THROW_IF_FAILED(cudaDeviceSynchronize());
return 0;
}
出力は以下になります
size: 4, thread_rank: 0
size: 4, thread_rank: 1
size: 4, thread_rank: 2
size: 4, thread_rank: 3
size: 4, thread_rank: 0
size: 4, thread_rank: 1
size: 4, thread_rank: 2
size: 4, thread_rank: 3
Thread Group Collective Operations#
Collective operationsは同期が必要だったり、特定のthreadとのコミュニケーションが必要な操作のことを指します。最も簡単な操作はグループ全体の同期です。これはsync()を使うことで可能になります。
g.sync();
cg::synchronize(g);
Thread Blocks#
thread_blockはkernelの中で thread block (= CUDA並列プログラミングにおける基本的な単位) を表す新しい型です。次のように初期化されます。
cg::thread_block block = cg::this_thread_block();
このthread_blockグループの同期は__syncthreads()と同じになります。つまり、以下の5つは同じ操作になります。
__syncthreads();
block.sync();
cg::synchronize(block);
cg::this_thread_block().sync();
cg::synchronize(this_thread_block());
thread_blockはthread_groupのインターフェースに加えblock特有の関数が追加されています。
dim3 group_index(); // 3-dimensional block index within the grid
dim3 thread_index(); // 3-dimensional thread index within the block
これはそれぞれCUDAでいうところのblockIdxとthreadIdxです。
__global__ void my_kernel() {
cg::thread_block block = cg::this_thread_block();
printf("group_index: (%d, %d, %d), thread_index: (%d, %d, %d)\n", block.group_index().x,
block.group_index().y, block.group_index().z, block.thread_index().x,
block.thread_index().y, block.thread_index().z);
}
int main() {
my_kernel<<<2, 4>>>();
THROW_IF_FAILED(cudaDeviceSynchronize());
return 0;
}
出力は次の通りです
group_index: (1, 0, 0), thread_index: (0, 0, 0)
group_index: (1, 0, 0), thread_index: (1, 0, 0)
group_index: (1, 0, 0), thread_index: (2, 0, 0)
group_index: (1, 0, 0), thread_index: (3, 0, 0)
group_index: (0, 0, 0), thread_index: (0, 0, 0)
group_index: (0, 0, 0), thread_index: (1, 0, 0)
group_index: (0, 0, 0), thread_index: (2, 0, 0)
group_index: (0, 0, 0), thread_index: (3, 0, 0)
(疑問) blockIdx/threadIdxとgroup_index/thread_idxはどう使い分けるべき?
Partitioning Groups#
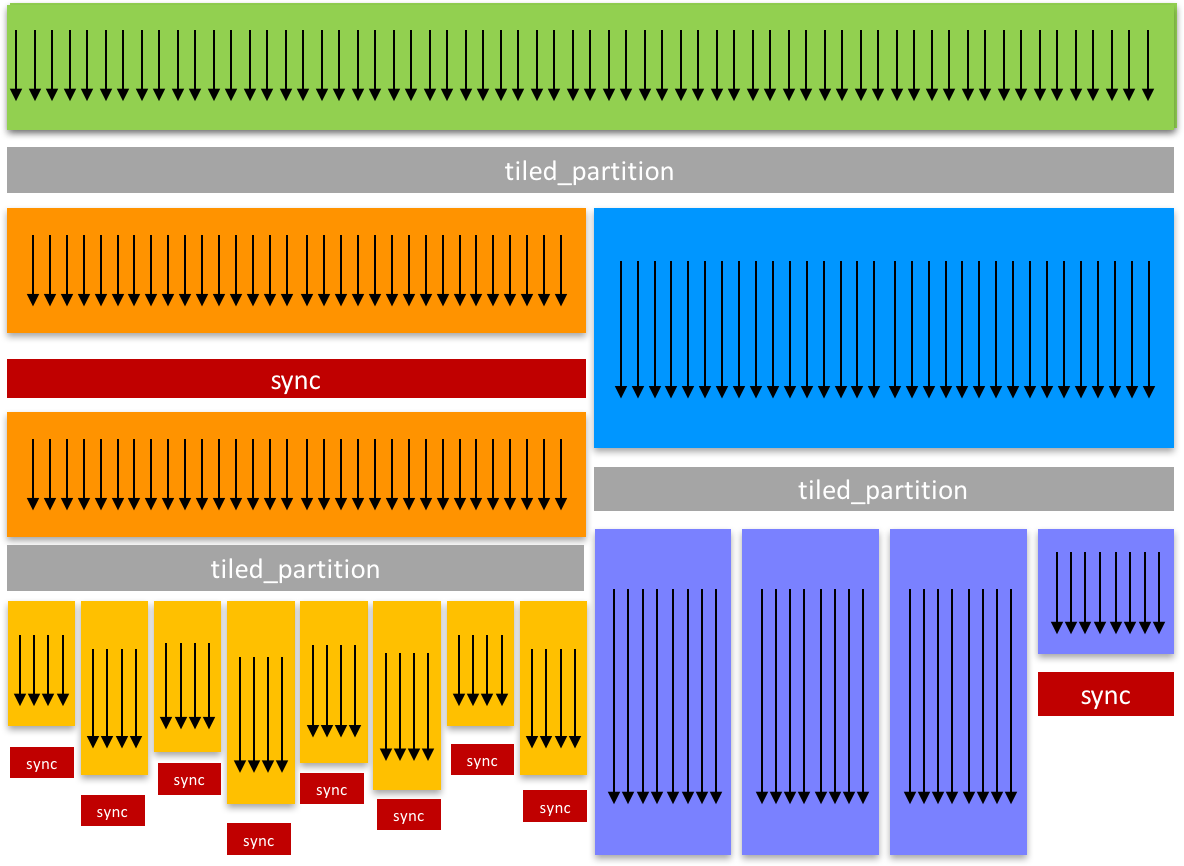
ここからがCooperative Groupsの本領発揮といったところでしょうか。groupを分割する機能についてみていきます。cg::tiled_partition()でblockを複数の"tile"に分割することができます。以下の例は、thread blockを32個のthreadを持つtileに分割する例です。
cg::thread_group tile32 = cg::tiled_partition(cg::this_thread_block(), 32);
それぞれのthreadが32-threadのグループへのhandleを得ます。さらに4-threadのtileに分割してみましょう
cg::thread_group tile4 = cg::tiled_partition(tile32, 4);
tiled_partition()によって作成されたthread groupも他のthread group同様の振る舞いをします。ここで、次の例を見てみましょう。
__global__ void my_kernel() {
cg::thread_block block = cg::this_thread_block();
cg::thread_group tile4 = cg::tiled_partition(block, 4);
if (tile4.thread_rank() == 0) {
printf("Hello from tile4 rank 0: %d\n", block.thread_rank());
}
}
int main() {
my_kernel<<<2, dim3{2, 16, 1}>>>();
THROW_IF_FAILED(cudaDeviceSynchronize());
return 0;
}
出力は次の通り
Hello from tile4 rank 0: 0
Hello from tile4 rank 0: 4
Hello from tile4 rank 0: 8
Hello from tile4 rank 0: 12
Hello from tile4 rank 0: 16
Hello from tile4 rank 0: 20
Hello from tile4 rank 0: 24
Hello from tile4 rank 0: 28
Hello from tile4 rank 0: 0
Hello from tile4 rank 0: 4
Hello from tile4 rank 0: 8
Hello from tile4 rank 0: 12
Hello from tile4 rank 0: 16
Hello from tile4 rank 0: 20
Hello from tile4 rank 0: 24
Hello from tile4 rank 0: 28
tile4は4つのthreadごとにthread_rank()が0になることがわかります
Modularity#
さまざまなthread groupのサイズに対して一貫したインターフェースを利用できるため、race conditionやdeadlockを防ぐことができます。
例えば、次のようなコードではdeadlockが発生します。
__device__ int sum(int *x, int n)
{
...
__syncthreads();
...
return total;
}
__global__ void parallel_kernel(float *x, int n)
{
if (threadIdx.x < blockDim.x / 2) {
sum(x, count); // error: half of threads in block skip
// __syncthreads() => deadlock
}
}
しかし、thread_blockを引数に取ることでこのようなdeadlockを防ぐことができます。
// Now much clearer that a whole thread block is expected to call
__device__ int sum(cg::thread_block block, int *x, int n)
{
...
block.sync();
...
return total;
}
__global__ void parallel_kernel(float *x, int n)
{
sum(cg::this_thread_block(), x, count); // no divergence around call
}
以下は32 threadのtileを使用したsum関数の例です。tileごとに合計を計算し、最終的にatomicAddで足し合わされます。
__global__ void sum_kernel_32(int *sum, int *input, int n)
{
int my_sum = thread_sum(input, n);
extern __shared__ int temp[];
auto g = cg::this_thread_block();
auto tileIdx = g.thread_rank() / 32;
int* t = &temp[32 * tileIdx];
auto tile32 = cg::tiled_partition(g, 32);
int tile_sum = reduce_sum(tile32, t, my_sum);
if (tile32.thread_rank() == 0) {
atomicAdd(sum, tile_sum);
}
}
(疑問) 上の方法だと1つのthreadごとにatomicAddするよりも速くなる?
Optimizing for the GPU Warp Size#
cg::tiled_partition()はtemplate parameterをとるバージョンもあります
cg::thread_block_tile<32> tile32 = cg::tiled_partition<32>(this_thread_block());
cg::thread_block_tile<4> tile4 = cg::tiled_partition<4> (this_thread_block());
これを使用することでreductionのコードを少し最適化することができます。
template <typename group_t>
__device__ int reduce_sum(group_t g, int *temp, int val)
{
int lane = g.thread_rank();
// Each iteration halves the number of active threads
// Each thread adds its partial sum[i] to sum[lane+i]
#pragma unroll
for (int i = g.size() / 2; i > 0; i /= 2)
{
temp[lane] = val;
g.sync(); // wait for all threads to store
if (lane < i) val += temp[lane + i];
g.sync(); // wait for all threads to load
}
return val; // note: only thread 0 will return full sum
}
また、tileのサイズがwarpのサイズと一致した時、compilerは同期を省略できる場合があります。熟練のプログラマがwarpを考慮した上で同期を取り除くことがよく行われるが、thread groupを明示的に同期するようなコードを書くことでrace conditionの発生を防ぐことができます (compilerが最適化してくれる?) 。
Warp-Level Collectives#
thread block tilesは次のwarp-levelなcollective functionをもつ。
.shfl()
.shfl_down()
.shfl_up()
.shfl_xor()
.any()
.all()
.ballot()
.match_any()
.match_all()
ここで、shfl_down()を使用したreductionのコードをみてみましょう。このコードではshared memoryを使用していません。
__device__ int thread_sum(int *input, int n) {
int sum = 0;
for (int i = blockIdx.x * blockDim.x + threadIdx.x; i < n / 4; i += blockDim.x * gridDim.x) {
int4 in = ((int4 *)input)[i];
sum += in.x + in.y + in.z + in.w;
}
return sum;
}
template <int tile_sz>
__device__ int reduce_sum_tile_shfl(cg::thread_block_tile<tile_sz> g, int val) {
// Each iteration halves the number of active threads
// Each thread adds its partial sum[i] to sum[lane+i]
for (int i = g.size() / 2; i > 0; i /= 2) {
val += g.shfl_down(val, i);
}
return val; // note: only thread 0 will return full sum
}
template <int tile_sz>
__global__ void sum_kernel_tile_shfl(int *sum, int *input, int n) {
int my_sum = thread_sum(input, n);
auto tile = cg::tiled_partition<tile_sz>(cg::this_thread_block());
int tile_sum = reduce_sum_tile_shfl<tile_sz>(tile, my_sum);
if (tile.thread_rank() == 0) {
atomicAdd(sum, tile_sum);
}
}
Discovering Thread Concurrency#
GPUでは32個のthreadからなるwarp単位でthread命令を実行します。コード内の条件分岐によってwarp内のthreadが分岐すると、アクティブなthreadとそうでないthreadに分かれます。アクティブなままでいるthreadはcoalescedと呼ばれます。Cooperative Groupsではこのようなthreadのgroupを取得するための関数を提供しています。
cg::coalesced_group active = cg::coalesced_threads();
例えば、次のような奇数のthread rankをもつthreadのみで計算を行う場合、アクティブなthreadのみに対して同期を実行できる。しかし、coalesced threadはwarpを跨ぐことはないため注意が必要である。
auto block = cg::this_thread_block();
if (block.thread_rank() % 2) {
cg::coalesced_group active = cg::coalesced_threads();
...
active.sync();
}
良い例として"warp-aggregation atomics"を考えてみましょう。warp-aggregationではwarpのthreadが増加分を合計したあと、その中の1つのthreadがグローバル変数のカウンタにアトミックに加算を行います。これによってatomic演算がwarpのサイズ分だけ減り、パフォーマンスがよくなります。
しかし、ここでキーポイントとなるのは、warpの最初のthreadでアトミック演算を行おうとしても、それがアクティブなthreadでない可能性があるということです。ここで、coalesced_groupのthread_rank()を使うことができます。
__device__ int atomicAggInc(int *ptr) {
cg::coalesced_group g = cg::coalesced_threads();
int prev;
// elect the first active thread to perform atomic add
if (g.thread_rank() == 0) {
prev = atomicAdd(ptr, g.size());
}
// broadcast previous value within the warp
// and add each active thread’s rank to it
prev = g.thread_rank() + g.shfl(prev, 0);
return prev;
}
実験#
さて、ここまでブログの記事をざっくりとみていきましたが、実際にコードを動かしてみましょう (今までもいくつか動かしていましたが…)
cg::thread_blockから取得できる情報をみていきます。一気に出力すると良く分からなくなるのでコメントアウトしながら動かします。
__global__ void my_kernel() {
cg::thread_block block = cg::this_thread_block();
dim3 dim_threads = block.dim_threads();
uint num_threads = block.num_threads();
uint get_type = block.get_type();
dim3 group_dim = block.group_dim();
dim3 group_index = block.group_index();
uint thread_rank = block.thread_rank();
uint size = block.size();
printf("dim_threads: (%d, %d, %d)\n", dim_threads.x, dim_threads.y, dim_threads.z);
// printf("num_threads: %d\n", num_threads);
// printf("get_type: %d\n", get_type);
// printf("group_dim: (%d, %d, %d)\n", group_dim.x, group_dim.y, group_dim.z);
// printf("group_index: (%d, %d, %d)\n", group_index.x, group_index.y, group_index.z);
// printf("thread_index: (%d, %d, %d)\n", thread_index.x, thread_index.y, thread_index.z);
// printf("thread_rank: %d\n", thread_rank);
// printf("size: %d\n", size);
}
int main() {
my_kernel<<<dim3{2, 3, 4}, dim3{5, 6, 7}>>>();
THROW_IF_FAILED(cudaDeviceSynchronize());
return 0;
}
dim_threads#
dim_threads: (5, 6, 7)
dim_threads: (5, 6, 7)
dim_threads: (5, 6, 7)
...
dim3{5, 6, 7}を返していますね
num_threads#
num_threads: 210
num_threads: 210
num_threads: 210
...
$5 \times 6 \times 7 = 210$個のthreadが実行されています
get_type#
get_type: 4
get_type: 4
get_type: 4
...
このtypeは以下の値に該当するようです。つまり、このblockのtypeはthread_block_idであることがわかります。
// cooperative_group.h
namespace details {
_CG_CONST_DECL unsigned int coalesced_group_id = 1;
_CG_CONST_DECL unsigned int multi_grid_group_id = 2;
_CG_CONST_DECL unsigned int grid_group_id = 3;
_CG_CONST_DECL unsigned int thread_block_id = 4;
_CG_CONST_DECL unsigned int multi_tile_group_id = 5;
_CG_CONST_DECL unsigned int cluster_group_id = 6;
}
group_dim#
group_dim: (5, 6, 7)
group_dim: (5, 6, 7)
group_dim: (5, 6, 7)
...
これもdim3{5, 6, 7}を返しています。
group_index, thread_idx#
...
group_index: (0, 0, 1)
group_index: (0, 0, 1)
group_index: (0, 0, 0)
...
...
thread_index: (4, 3, 0)
thread_index: (0, 4, 0)
thread_index: (1, 4, 0)
...
こちらについては先ほど紹介した通りblockIdx/threadIdxと同じですね
size#
...
size: 210
size: 210
size: 210
...
これは$5 \times 6 \times 7$と一致します。
thread_rank#
...
thread_rank: 189
thread_rank: 190
thread_rank: 191
thread_rank: 64
thread_rank: 65
thread_rank: 66
...
この値は0から209まで取るかと思ったのですが、調べてみると0から191までのようです。6つ分のwarpのみ動いているということでしょうか。ここで気がついたのですが、標準出力の行数も4608 ($= 2 * 3 * 4 * 192$) となっていました。192から209番目のthreadは実行されていないのは、今回のコードがただprintfするコードのためcompilerによる最適化がかかったと考えられます。
続きは余力があれば…