One-Shot Free-View Neural Talking-Head Synthesis for Video Conferencing を読む
One-Shot Free-View Neural Talking-Head Synthesis for Video Conferencing という論文を読んでいきます。CVPR 2021にacceptされています (本文中の図は論文より引用) 。

Motivation#
Contrubutionは次の通り
- 新しいone-shot neural talking-head synthesis手法の提案。ベンチマークよりも良いクオリティの画像を生成できる。
- 3Dグラフィックモデルなしで、出力動画のviewの操作ができる。
- ビデオのバンド幅を削減できる。H.264より10倍バンド幅を削減できることがわかった。
Method#
手法は大きく分けて3つのステップからなる。
- source image feature extraction
- driving video feature extraction
- video generation
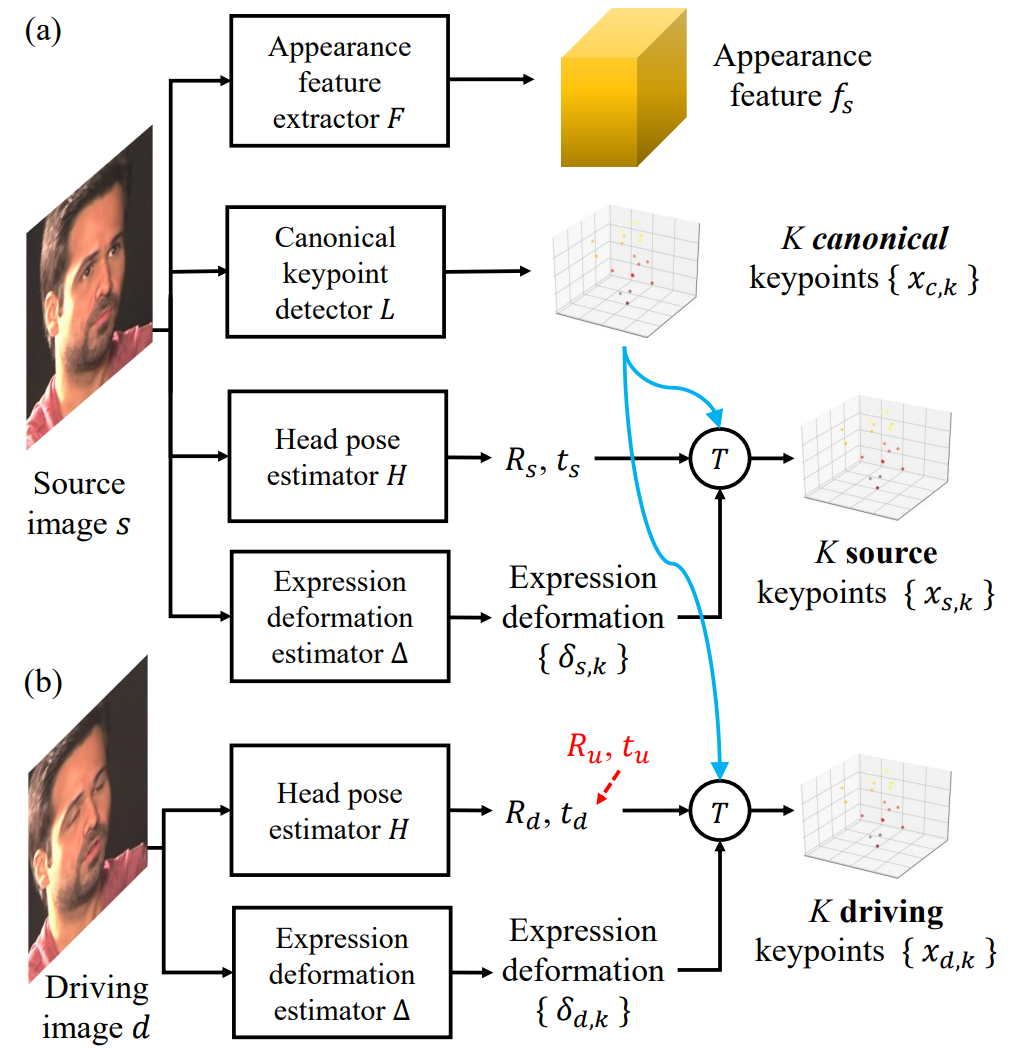
1. Source image feature extraction#
上の画像 (a) の操作。
Appearance feature extractor $F$ をつかってappearance feature $f_s$を得る。 この $f_s$ は3次元のテンソルであり、このようにすることで3Dの操作 (rotationやtranslation) が可能になる。
canonical 3D keypoint detector $L$ をつかって $s$ から $K$ 個の3D keypoints: $x_{c,k} \in \mathbb{R}^3$ を得る (この論文では $K=20$ ) 。このkeypointは教師なしで学習されるものであり、標準的な顔のランドマークとは異なる。また、取ってきたkeypointはposeやexpressionとは独立である。
Head pose estimator $H$をつかってRotation行列 $R_s\in\mathbb{R}^{3 \times 3}$ とtranslation行列 $t_s\in\mathbb{R}^3$を得る。
Expression deformation estimator $\Delta$ をつかって $K$個の3D deformations: $\delta_{s, k}$ を得る。 deformationはneutral expressionからの変形を表している。
最終的に、transformation $T$ を通してsource 3D keypoint: $x_{s, k}$を得る。 $$ x_{s, k} = T(x_{c,k}, R_s, t_s, \delta_{s,k}) \triangleq R_sx_{c,k} + t_s, \delta_{s, k} $$This decomposition has several benefits:
2. Driving video feature extraction#
上の画像 (b) の操作。
$d$ は動画 $\lbrace d_1, d_2, \ldots, d_N\rbrace$ の中の1つのフレームを表すこととする。
Source image feature extractionと同様に
Head pose estimator $H$ をつかって $R_d$ と $t_d$ を得る。
また、expression deformation estimator $\Delta$ をつかって $\delta_{d,k}$ を得る。
これと、先ほど導出した $x_{c,k}$ をつかってdriving keypointを得る。
$$This decomposition has several benefits:angleq R_d x_{c,k} + t_d, \delta_{d, k}
$$
出力画像はsource画像と同じidentityを持つという前提があるため $x_{c, k}$ はsource imageで抽出したものをそのまま使用できる。
ここで、ユーザはRotationとtranlationを操作することができる。 $$ R_d \leftarrow R_u R_d, \ t_d \leftarrow t_u + t_d $$
3. Video generation#
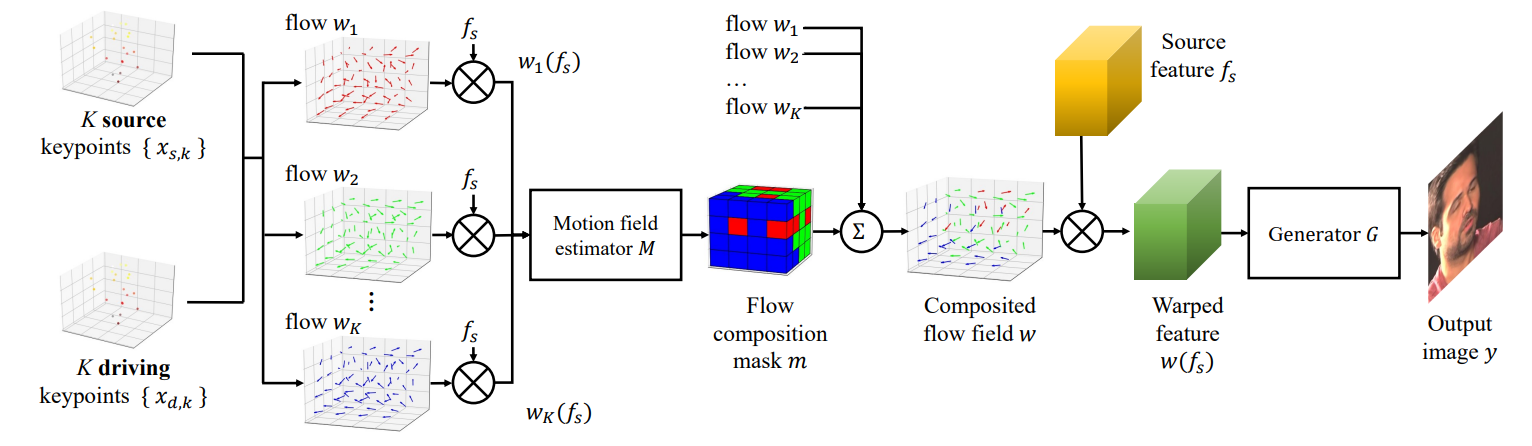
Training#
Perceptual loss $\mathcal{L}_p$ and GAN loss $\mathcal{L}_G$#
outputとdriving imageの間のloss。GAN lossはpatch levelで行われる。
Equivariance loss $\mathcal{L}_E$#
導出されたkeypointが良いkeypointならば、imageに2D transformationを加えると、そのkeypointがそのtransformationに従って変わるだけという前提に基づいている。
Keypoint prior loss $\mathcal{L}_L$#
$x_{d, k}$ が顔の範囲中に広がるようにするためのloss。 それぞれのkeypoint間の距離を計算し、準備したしきい値よりも小さいと損失が与えられる。
Head pose loss $\mathcal{L}_H$#
予測したHead poseと正解値のHead poseの間のloss。 正解値はpretrainedのモデルで導出する。
Deformation prior loss $\mathcal{L}_\Delta$#
Deformation $\delta_{d, k}$ はexpressionの変化を表すパラメータなので、大きくならないようにlossが設計されている。
これらのlossを足したものが最小化されるように設計する。
Experiments#
Optimization#
ADAMでlossの最小化を測る ($\beta_1 = 0.5, \beta_2 = 0.999$)。 learning rate = 0.0002で、generatorとdiscriminatorのレイヤー全てにSpectral Normを適用する。 また、synchronized BatchNormをgeneratorに適用する。 最初に256x256の画像で100 epoch学習したあと、512x512の画像で10 epoch学習する。
Datasets#
- VoxCeleb2
- TalkingHead-1KH
新しく集められたデータセット。VoxCeleb2に比べて高品質で高い解像度をもつ。
Result#
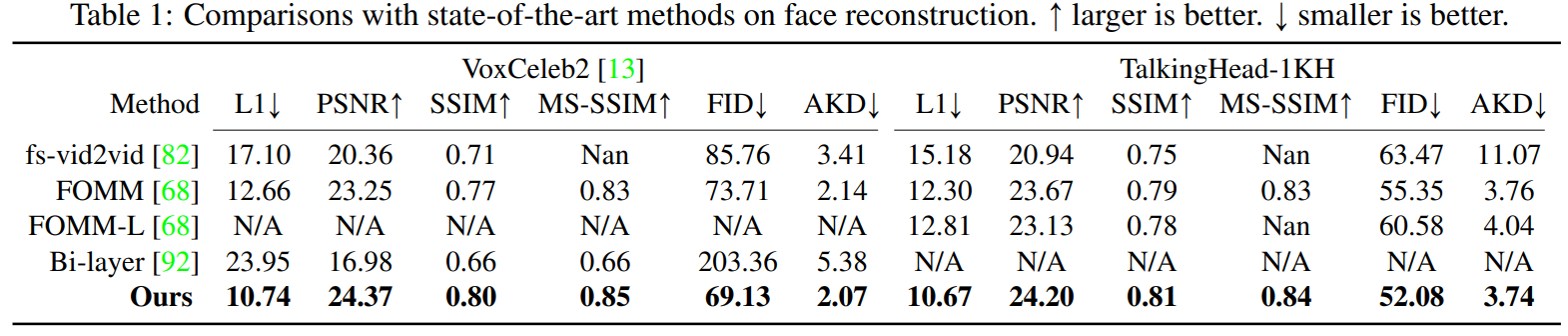


また、他の人物にmotion-transferさせたときや、顔の方向を変えたときの結果を以下に示す。

References#
- project page
- unofficial implementation

Memo#
発想が独特で、facial landmark (のようなもの) を教師なし学習で学習するなど、凝っている手法である。 また、省略したが、顔の向きや表情などがパラメータ化されるので少ないデータ量で顔を再現できるというのも面白い。 公式にコードは公開されていないがunofficial repositoryが存在するため、コードレベルで実装を確認することができる。