Taskonomyを読む
Taskonomy: Disentangling Task Transfer Learning という論文を読んでいきます。 この論文はCVPR 2018のBestPaperを受賞しています (本文中の図は論文より引用) 。
Motivation#
タスク間の転移学習しやすさが分かれば、アノテーションの足りないデータを扱う、または性能を向上させたいときにどのタスクで事前学習を行うべきかが分かる。
Method#
手法は「sourceタスク$\rightarrow$targetタスクで転移学習し、誤差を比較する」という流れです。
用意したsourceタスクの集合を$\mathcal{S}$、targetタスクの集合を$\mathcal{T}$とします。
今回は$|\mathcal{S}| = 26, |\mathcal{T}|=22$となっています (source-onlyタスクが4種類) 。
1. Task-Specific Modeling#
Sourceタスクそれぞれで教師あり学習を行います。 ネットワークはエンコーダとデコーダを持ちます。エンコーダの構造は同一 (ResNet50を修正したもの) ですが、デコーダの構造はタスクによって異なります。
2. Transfer Modeling#
$s\in \mathcal{S}$ と $t\in \mathcal{T}$ が与えられたとき、$s\rightarrow t$ と転移学習を行ったときの$t$でのパフォーマンスを求めます。 このとき、エンコーダは $s$ で学習したもので固定し、$t$ でデコーダのみ学習させます。
3. Analytic Hierarchy Process (AHP) による正規化#
転移学習しやすさのAffinity Matrix (相性の行列) を計算します。
直感的には、「 $s\rightarrow t$ に転移学習したときの最終的な$t$でのテスト誤差をそのまま $[0, 1]$ にスケールさせて用いる」という方法が考えられますが、そうすると
テスト誤差に対しての本当のクオリティが変わるスピードが異なる場合に問題となります (例えば、Segmentationでの誤差が1/2になるのと、edge検出での誤差が 1/2 になるのは同じだけ性能が向上したとは言えません) 。
つまり、何かしらの方法を用いて正規化しなければいけません。
そこでAHP法 (固有値を用いる方法 参考
) を用います。
AHP法を用いると、ある$t\in\mathcal{T}$に対してどの$s\in\mathcal{S}$が重要 (効率的) なのかが分かります。つまり、ある$t$に対して、$i$番目が$s_i$の重要性を表すようなベクトル$\mathbf{s}\in \mathbb{R}^{|\mathcal{S}|}$が得られるということです。
すべての$\mathcal{T}$について重要性を計算したあと、$(i, j)$要素が$t_i$に対する$s_j$の重要性を表すようにベクトルを結合していくと、Affinity Matrixを求めることができます (下図右) 。 ここで、下図左の行列は正規化を行わなかったときのAffinity Matrixを表しており、正規化することで違いが理解しやすくなっていることが分かります。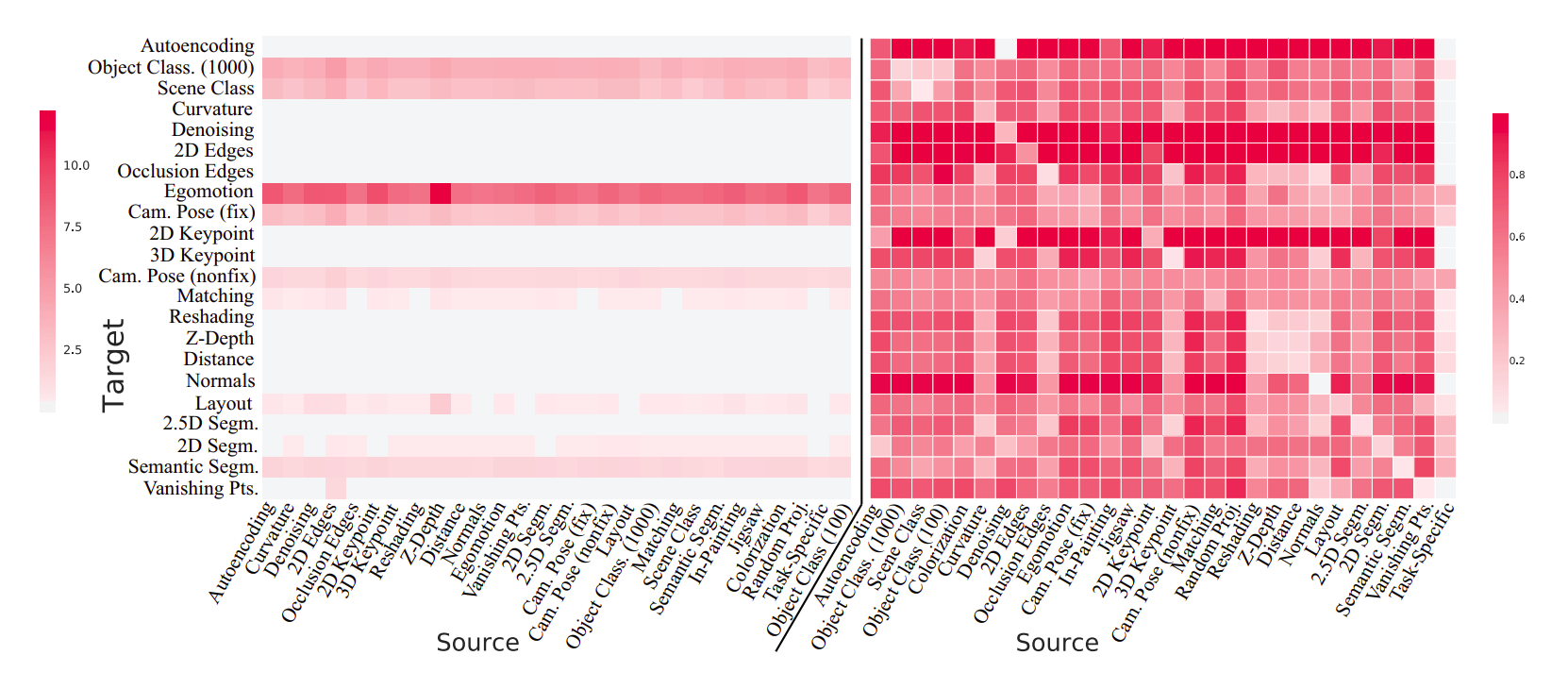
4. Computing the Grobal Taxonomy#
さて、Affinity Matrixが与えられたとき、$t\in \mathcal{T}$のパフォーマンスを最大化する$\mathcal{S}$の部分集合を考えます。 これは、与えられた予算の中で目標を最大化させるという問題に帰着し、整数計画法 (Boolean Integer Programming; BIP) を用いて解くことができます。
Result#
おそらく論文よりプロジェクトサイト のAPIを見たほうが早いです。 $\mathcal{S}, \mathcal{T}$、そして予算などを指定してあげると、どのタスクがどのタスクに効率的に転移学習が行えるかが表示されます。
Memo#
約48000時間GPUで計算したというこの論文。圧倒的な資金力。